
« Chez ACME (remplacez ce nom par toute entreprise souhaitant se donner une image innovante) nous avons développé un IA Lab avec des data scientists et des experts en intelligence artificielle qui expérimentent tous les jours en Machine Learning et Deep Learning ! »
Vous avez déjà entendu ce genre de phrase qui ne veut finalement pas dire grand-chose ?
On observe actuellement des développements d’IA ou de Data Lab en entreprise qui ressemblent plus à des projets de communication qu’à une réponse à un vrai besoin.
Avec l’essor récent de l’intelligence artificielle, il semble essentiel pour toutes les entreprises de développer rapidement un Data / IA Lab et les bases du développement logiciel sont souvent passées à l’as.
Chez Suricats Consulting, nous avons pu constater une absence de retour sur investissement dans la plupart des Labs de nos clients. Alors, comme nous sommes curieux et soucieux de répondre aux douleurs de nos clients, nous avons eu envie de creuser le sujet.
Dans cet article nous vous proposons de découvrir nos convictions sur le sujet des Data Labs en détaillant 3 de nos 8 commandements pour passer d’un Data Lab peu générateur de projets à une Usine IA qui délivre des solutions à grande échelle, en production.
1 – Cas d’usage : ne pas mettre toute son énergie sur un use case « star »
Une des premières choses que l’on remarque lorsqu’une entreprise souhaite développer un Data / IA Lab est la volonté de choisir le cas d’usage star sur lequel on va miser la réussite du Lab.
Dans ce cas, la volonté de l’entreprise est de sortir un projet technologiquement impressionnant et cela mobilise souvent beaucoup de membres de l’organisation.
Or, les équipes techniques, c’est à dire les développeurs et architectes logiciels, ne sont pas toujours préparées ni formées à intégrer des technologies d’IA. Et les équipes métiers ne connaissent pas assez la complexité du domaine et proposent donc souvent des cas d’usages bien trop complexes pour débuter.
« Le risque pour le data / IA lab : démarrer avec des cas d’usages trop complexes »
Le résultat-catastrophe, mais malheureusement courant, de ce type de projet est alors qu’il tombe à l’eau et les différentes équipes de l’organisation sont démotivées et réticentes à l’idée de retravailler sur ces sujets.
Pour éviter de tomber dans ce cas de figure, une solution très simple est le travail par itérations : il faut commencer par se faire la main sur des sujets à faible complexité et former en parallèle les collaborateurs.
De cette manière, les équipes techniques auront le temps de mettre en place les infrastructures nécessaires. Il sera donc plus simple de travailler avec les données, par étapes, en commençant par exploiter ce qui est exploitable dans le SI, plutôt que de lancer un grand et laborieux chantier.
« Travailler par itérations, en commençant là où la donnée est déjà exploitable »
Il sera alors plus simple d’identifier des petits projets avec un ROI rapide et ainsi de mettre le Lab au service de l’entreprise et de son business. Il n’est malheureusement pas rare de trouver des équipes spécialisées en IA qui sont complètement déconnectées des problématiques business et dont les projets n’entrent jamais en production.
Une autre problématique que l’on rencontre souvent lors de la mise en place d’un Data Lab, et qui constitue un réel frein à la mise en production des projets d’IA, est l’intégration des équipes IA aux équipes techniques.
Ce qui nous amène à notre second commandement.
2 – Processus projet : un projet tech reste un projet tech
Prenons un exemple concret : les applications mobiles.
Si, demain, une entreprise souhaite développer une nouvelle application mobile, comment va-t-elle s’y prendre ? Va-t-elle engager un ou plusieurs développeurs, les laisser dans un coin de l’organisation, et leurs demander d’expérimenter autour d’un sujet ?
Non. Ou du moins nous l’espérons !
L’application devra s’intégrer au SI et répondre aux mêmes exigences que le reste de l’usine logicielle de l’entreprise. Les développeurs seront intégrés aux différentes équipes de l’organisation et devront peut-être mettre en place un pipeline d’intégration continue, développer des tests et industrialiser leur projet comme n’importe quel autre projet de l’organisation.
La future application mobile devra utiliser et enregistrer des données, communiquer avec d’autres applications et sera amenée à évoluer de la même manière que tout autre projet. Alors pourquoi faire une distinction pour les projets d’IA ?
Les cas d’usage doivent être pensés pour s’intégrer au SI et exploiter les ressources déjà existantes. De ce fait, le projet d’intelligence artificielle doit pouvoir s’interfacer aux autres applications de l’organisation.
« APIs et stores applicatifs, facilitateurs de projets »
Une bonne pratique que l’on retrouve dans certaines entreprises est de développer des stores applicatifs qui permettent à chaque membre de l’organisation de consulter les modèles d’IA développés et donner accès à la documentation de l’interface, souvent une API. L’APIsation des modèles est en effet l’un des meilleurs moyens pour permettre aux équipes techniques d’exploiter facilement ces projets et de les intégrer aux applications déjà existantes.
De la même manière, il est important que les équipes techniques comprennent les enjeux et le fonctionnement des modèles en production. Les développeurs ont souvent du mal à comprendre comment les projets d’IA vont pouvoir apporter de la valeur aux applications déjà existantes dans l’entreprise. Pour simplifier cette compréhension, nous sommes convaincus de l’importance d’intégrer le Data / IA Lab au reste des équipes techniques pour comprendre les bases d’architecture logicielle et construire ainsi des modèles pérennes et robuste.
« Vers une Usine IA productive »
En effet, souvent, les développeurs en IA viennent du monde des statistiques et n’accordent pas beaucoup d’importance à l’architecture technique. De la même manière les équipes techniques connaissent les données de l’entreprise et les contraintes liées au SI et elles pourront identifier les cas d’usages qui pourraient être exploités et les blocages que pourraient rencontrer certains projets.
Si l’industrialisation est un des facteurs clés d’une Usine IA productive, c’est aujourd’hui un des points de blocage majeur et le sujet de notre prochain commandement.
3 – Pipeline et outils : vers une Industrialisation de votre LAB
Nous avons observé que les projets d’Intelligence artificielle sont plus difficilement industrialisables que des projets de développement logiciel plus « classiques ». C’est principalement dû au fait que ces sujets sont assez nouveaux dans le monde de l’entreprise et que les bonnes pratiques commencent tout juste à émerger.
« Des pratiques d’industrialisation encore jeunes … et des bonnes pratiques encore à construire et affiner »
Dans ces bonnes pratiques nous retrouvons la définition de pipeline de développement propre à l’IA, il existe des plateformes à destination des data scientists et des développeurs, des outils pour simplifier la mise en place de leur projet. Ces plateformes sont communément appelées ‘plateformes d’auto-ML’.
De la normalisation des données à la mise en production sous forme d’API, ces plateformes peuvent être un premier pas dans l’industrialisation d’un Data / IA Lab. Les entreprises les plus matures sur le sujet, comme Uber par exemple avec le projet Michelangelo, développent leurs propres pipelines qui leur permettent d’être plus flexibles que sur des plateformes d’auto-ML génériques.
Parmi les leaders sur le marché de ces plateformes, on retrouve Dataiku, Datarobot ou encore H2O.ai. Ces plateformes permettent aux datascientists de récupérer et visualiser facilement des données qu’elles soient extraites depuis une BDD locale ou hébergée. Elles intègrent un grand nombre d’algorithmes et de modèles existants qui peuvent être réutilisés et ajustés via une interface graphique ou en programmation. Leur grande force est l’automatisation de la recherche d’algorithme !
« Utiliser des plateformes d’Auto-ML, une bonne manière de démarrer »
Si une organisation ne dispose pas de ressources techniques ou si elle veut s’essayer facilement au développement de modèles de Machine Learning et Deep Learning, ces plateformes peuvent être une bonne solution pour débuter. Néanmoins, avec des problématiques métiers et des données complexes, le risque est de vite manquer de marge de manœuvre.
Il est important de comprendre qu’un projet de type système expert et un projet de Machine Learning ou même de Deep Learning ne suivent pas les mêmes étapes de développement, et n’ont pas besoin des mêmes ressources, il est nécessaire de les séparer en différents pipelines de développement.
« Un projet à base d’algorithmes d’intelligence artificielle ne suit pas les mêmes étapes qu’un projet IT classique »
Pour illustrer ce propos, un sujet qui sera qualifié « d’intelligence artificielle » peut très bien se résumer juste à un chatbot avec un système de règles décrites longuement par un développeur. Son pipeline de développement ressemblera beaucoup à n’importe quel autre projet de développement logiciel avec des tests unitaires et une intégration continue. Une fois en production, le projet n’évolue qu’avec de nouveaux développements.
A contrario, si l’on prend un projet de Deep Learning, la phase de développement sera surement la plus simple (dans le cas où le développeur utiliserait des framework de DL comme TensorFlow), la récupération et l’exploitation des données beaucoup moins. Dans les pipelines de développement de modèles de Machine Learning, nous retrouvons souvent une plateforme de mise en commun des datasets normalisés qui permet aux data scientists de gagner énormément de temps, car bien souvent la majorité des modèles de l’organisation vont exploiter les mêmes données.
Dans ces pipelines, nous retrouvons une grande partie sur le monitoring des modèles en production, car la performance d’un modèle en production dépend de l’évolution des données de l’entreprise. Nous ne détaillerons pas cette partie dans cet article mais n’hésitez pas à nous contacter si vous voulez plus d’informations sur le sujet.
Productivité et R.O.I. positif : il est temps de transformer les IA / Data Labs en Usine IA !
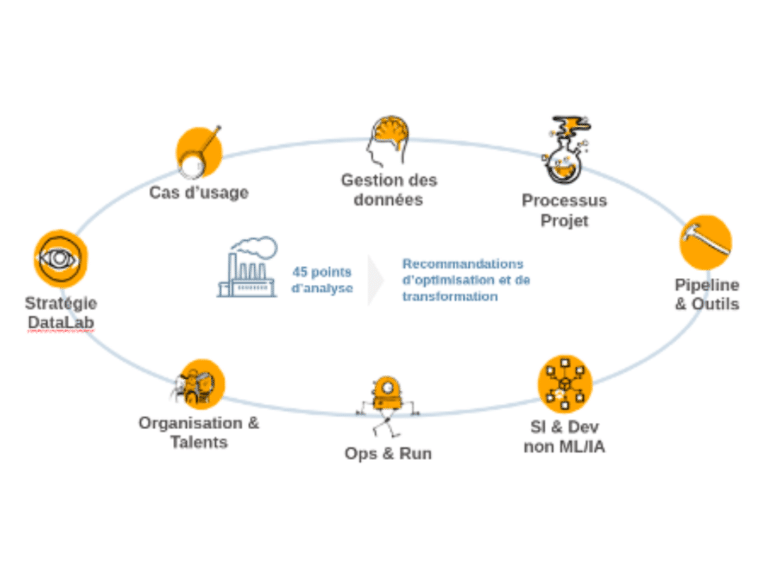
Les trois commandements détaillés ci-dessus font partie d’un ensemble de huit grands axes que nous évaluons pour mieux comprendre les douleurs d’un Data Lab.
Nous avons ainsi développé une grille de maturité en 8 axes et 45 points d’analyse qui nous permet de définir rapidement les leviers principaux à activer pour industrialiser le Lab :
Si vous voulez en savoir plus n’hésitez pas à nous contacter.


