C’est un sujet qui n’est pas nouveau, la maîtrise des données métiers est un enjeu majeur de toute entreprise qui cherche à mieux piloter les leviers de sa performance.
Avec l’évolution des technologies, en particulier la place de plus en plus importante de l’IA, la maîtrise de la Data est aujourd’hui plus cruciale que jamais. Difficile de passer à côté des annonces sur les usages de l’IA générative (ex ChatGPT – OpenAI) qui vont avoir de multiples impacts sur nos modes de fonctionnement. Et, l’IA ne sait fonctionner correctement que si les données sont suffisantes en volume et en qualité.
On peut partir d’un premier constat, la transformation digitale des entreprises a concrètement changé la culture autour de cette notion. La plupart des organisations se sont dotées d’un CDO (Chief Data Officers) depuis quelques années, dont l’objectif majeur a été et est encore de valoriser les données. La digitalisation est en marche « forcée », mais nous ne sommes pas encore au bout de ce chemin. On constate qu’il y a encore beaucoup à faire sur certaines activités encore mal documentées, mal outillées et qui génèrent parfois beaucoup de stress à ceux qui les opèrent.
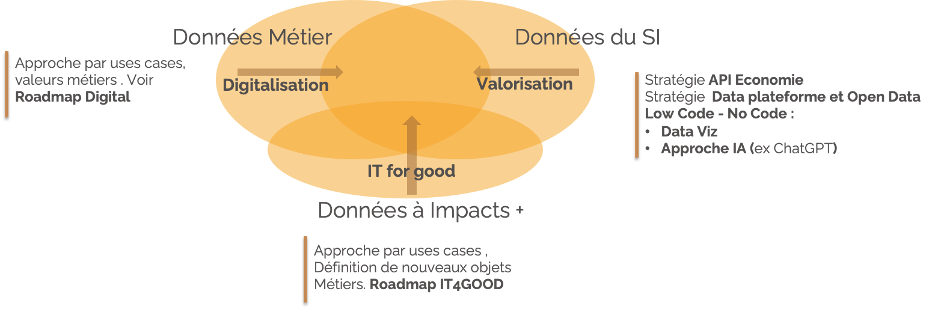
Chez Suricats, nous pensons que pour construire une feuille de route efficace autour de la valorisation de la data, il faut construire une trajectoire de transformation autour de 3 volets complémentaires :
- Définir les opportunités de « digitalisation » des activités pour enrichir le patrimoine de donnée ;
- Tirer parti des données du SI existant pour les valoriser ;
- Intégrer la « data à Impact + » pour rentrer sur les enjeux du numérique responsable ;
Définir les opportunités de « digitalisation » des activités
Sur cette question, les choses évoluent très vite. De nouvelles technologies arrivent à maturité en particulier sur le marché de l’IOT (Internet des objets) « industrielle », avec un nombre croissant de start-up tech autour des architectures de type “Smart Edge Computing” et sur les solutions de réalité virtuelle, suivre en particulier la société Meta et sa proposition autour du Metaverse. Avec le support de ces technologies, de nouvelles données métiers jusqu’alors difficile à collecter sont accessibles et offre des opportunités de valoriser de nouveau cas d’usage à digitaliser.
Bonne pratique et recommandation :
Un objet métier se définit sur la base d’un vocabulaire communément accepté dans l’entreprise ou au sein d’une norme partagé dans un secteur d’activité. Quelques étapes clés :
- Mettre en place un dictionnaire de donnée et cartographier les objets métiers (ontologie)
- Décrire le cycle de vie (création, mise à jour, retrait) à chaque étape du processus métier.
Une tendance en particulier : la Digital Twin.
La « Digital Twin » (ou jumeau numérique en français) est un concept de plus en plus répandu dans le domaine de la technologie et de l’industrie. Il désigne une réplique virtuelle d’un objet, d’un système ou d’un processus réel. Plus précisément, c’est une représentation numérique en temps réel d’un objet physique ou d’un système, créée à l’aide de données et de modèles numériques.
Le concept de Digital Twin repose sur l’idée que les objets physiques peuvent être jumelés avec leur équivalent numérique, permettant ainsi de surveiller, d’analyser et de simuler le fonctionnement de l’objet réel dans un environnement virtuel. Grâce à cette représentation numérique, il est possible de suivre en temps réel l’état et le comportement de l’objet réel, de prédire son fonctionnement futur, de tester des scénarios et d’effectuer des analyses de performance.
Les applications des Digital Twins sont vastes et concernent de nombreux domaines tels que l’industrie manufacturière, l’aérospatiale, l’énergie, les transports, la santé, et même la gestion de villes intelligentes. Par exemple, dans le domaine de la fabrication, une Digital Twin peut être utilisé pour surveiller et optimiser le fonctionnement d’une machine, anticiper les pannes, ou simuler de nouveaux processus de production.
L’utilisation des digital Twins peut apporter des avantages considérables en termes d’efficacité, d’optimisation des opérations, de réduction des coûts et de prise de décisions éclairées. Cependant, leur mise en œuvre nécessite une collecte de données précises, des modèles numériques sophistiqués et des capacités d’analyse avancées pour créer une représentation précise et fiable de l’objet ou du système réel.
Tirer parti des données du SI existant
Le patrimoine de donnée dans le SI se caractérise pour une très large partie des représentations numérisées des données métiers, rangées dans des bases de données structurés. Il existe aussi d’autres données plus « techniques » qui tracent l’activité du système d’information (trace les modifications des données au sein du SI) mais qui deviennent une source de valorisation quand on rentre dans une démarche orientée événement (EDA – Event Driven Architecture). On peut rajouter aussi les « Métadonnées », qui enrichissent la donnée métier pour les usages numériques.
D’autre part, une partie des données, de plus en plus conséquente en volume, ne s’intègrent pas dans un modèle, elles sont appelés données non-structurées, comme par exemple le contenu d’une boite d’email ou bien une bibliothèque de document numérique (Guides d’utilisisation, contrats, présentations,…) au format PDF , des images ou encore plus actuel, les conversations sur les réseaux sociaux professionnels. Ces données sont autant de richesse d’information pour l’entreprise, à exploiter dans le sens d’une meilleure capitalisation sur les savoir-faire et un accès simplifié à l’information. L’IA pourrait devenir le meilleur allier des collaborateurs dans ce cas précis.
Avec le temps, les SI des entreprises se sont complexifiées et la maîtrise du cycle de vie de la donnée est un réel challenge. Il est donc essentiel de comprendre les données disponibles :
- Bien caractériser les données (Catalogue / Dictionnaire) qui sont stockées dans le SI, où elles sont stockées et comment elles sont structurées. Identifier les sources de données pertinentes pour les objectifs de valorisation. Si les données sont dispersées dans différentes bases de données ou systèmes, il y a sans doute des opportunités de mettre en place un processus pour les centraliser dans un entrepôt de données (data Warehouse) afin de faciliter leur accès et leur usage.
- Vérifier si les données nécessaires sont collectées de manière régulière et fiable. Il sera peut-être nécessaire de mettre à jour les processus d’enregistrement des données si certaines informations clés sont manquantes. Une attention particulière est à faire aussi sur les données sensibles pour les sécuriser conformément aux règles de confidentialité et de conformité en vigueur. L’accès aux données doit être contrôlé pour éviter tout accès non autorisé.
- Améliorer continuellement le processus : L’analyse des données ne doit pas être une tâche ponctuelle. Il est important de mettre en place un processus d’amélioration continue pour affiner les méthodes d’analyse, collecter de nouvelles données pertinentes et ajuster les objectifs en fonction des résultats obtenus.
Pour définir la stratégie data, les axes de valorisation sont multiples et complémentaires :
Améliorer le pilotage des activités (Data visualisation, Reporting) : Cet axe vise à utiliser la donnée pour améliorer la prise de décision et la gestion des activités au sein de l’organisation. Cela peut être réalisé en développant des tableaux de bord interactifs et des rapports détaillés basés sur des données en temps réel. Ces outils de data visualisation permettent aux décideurs de mieux comprendre les performances, les tendances et les problèmes potentiels, facilitant ainsi la prise de décision éclairée.
Automatiser certaines activités à faible valeur ajoutée : En utilisant des techniques d’automatisation basées sur les données, l’organisation peut libérer du temps et des ressources en réduisant les tâches répétitives et à faible valeur ajoutée. L’automatisation permet de traiter rapidement et avec précision des processus qui, autrement, nécessiteraient une intervention humaine, améliorant ainsi l’efficacité opérationnelle.
Faciliter le partage et la consommation de la donnée dans l’organisation : Une stratégie data efficace implique de mettre en place des solutions pour faciliter le partage et l’accès à la donnée à travers les différents départements et niveaux hiérarchiques de l’organisation. Cela peut inclure la mise en place de plateformes de partage de données sécurisées, l’adoption de normes et de protocoles de gestion de la donnée, ainsi que la sensibilisation et la formation des employés à l’utilisation responsable des données.
Ouvrir les données aux partenaires ou en Open innovation : Cette approche consiste à partager certaines données de l’organisation avec des partenaires externes, comme des fournisseurs, des clients ou des acteurs de l’écosystème, dans un but de collaboration ouverte (Open innovation). Cela peut stimuler la cocréation, favoriser de nouvelles opportunités commerciales et accélérer l’innovation.
Prédire et adapter les activités le plus rapidement possible en fonction du contexte (interne et externe) : En utilisant des techniques d’analyse prédictive, l’organisation peut anticiper les tendances, les changements du marché et les besoins des clients. En conséquence, elle peut adapter ses activités plus rapidement et de manière plus proactive pour rester compétitive et répondre aux attentes changeantes du marché.

Aujourd’hui un large panel de solutions technologiques apporte un support à la démarche de valorisation en fonction de la stratégie data que l’on souhaite mettre en place :
- L’ « API Economy, API MarketPlace » : Approche de valorisation pour l’interne (faciliter le réuse) et/ou en Open API (Monétisation à la consommation). L’API Economy (Économie des API) se réfère à l’écosystème économique qui découle de l’utilisation croissante et de la commercialisation des interfaces de programmation d’applications (API). Une API est un ensemble de règles et de protocoles qui permettent à différentes applications logicielles de communiquer et d’échanger des données entre elles. L’API Economy est une conséquence de la numérisation et de la connectivité croissantes des entreprises et des services, car elle permet aux entreprises de partager leurs fonctionnalités et leurs données avec d’autres entreprises et développeurs, leur permettant ainsi de créer de nouveaux produits et services innovants.
- L’Approche data plateforme et Open Data : Master Data Management (MDM = PIM + DAM + CMS) et les Modèles de monétisation des données. Cette approche vise à rassembler toutes les données dispersées dans différents systèmes et départements au sein d’une plateforme unique, facilitant ainsi leur utilisation et leur partage entre les différentes équipes. L’Open Data fait référence à une approche différente, où les données sont mises à disposition du public de manière libre, gratuite et souvent dans des formats accessibles et réutilisables. L’idée derrière l’Open Data est de promouvoir la transparence, l’innovation et la participation du public en fournissant un accès ouvert à des ensembles de données qui étaient auparavant inaccessibles ou restreints.
- L’IA, Approche pour enrichir la donnée, Offrir des opportunités d’automatisation d’activité à peser en fonction des impacts humains. Deux types d’IA à regarder : les Modèles prédictifs et les modèles génératifs. Avant tout, Il est essentiel de considérer attentivement les implications éthiques et sociales de l’utilisation de l’IA afin de minimiser les impacts négatifs potentiels sur les individus et la société.
- Enrichir les données avec l’IA : L’IA peut être utilisée pour enrichir les données existantes en les nettoyant, les corrigeant ou en les complétant. Les algorithmes d’apprentissage automatique, tels que les réseaux de neurones peuvent analyser de grandes quantités de données pour identifier des schémas, des relations ou des valeurs manquantes. Ces modèles prédictifs peuvent être utilisés pour remplir les lacunes dans les enregistrements de données et créer des jeux de données plus complets et précis. Par exemple, dans le domaine de la reconnaissance vocale, les systèmes basés sur l’IA peuvent analyser des enregistrements audios pour identifier et corriger les erreurs de transcription, améliorant ainsi la précision du système dans son ensemble. Par exemple, dans le domaine de la gestion de la relation client, des chabots basés sur l’IA peuvent être utilisés pour répondre aux questions fréquemment posées par les clients, soulageant ainsi les agents du service clientèle des tâches répétitives.
Automatisation d’activités avec l’IA : L’IA peut également être utilisée pour automatiser des tâches et des activités qui étaient traditionnellement effectuées par des humains. Ces tâches peuvent être répétitives, fastidieuses ou nécessiter un traitement rapide de grandes quantités de données. L’automatisation par l’IA peut libérer du temps pour les êtres humains afin qu’ils puissent se concentrer sur des tâches plus complexes et créatives.
Modèles prédictifs : Les modèles prédictifs sont des modèles d’IA conçus pour effectuer des prédictions basées sur des données historiques. Ils analysent les modèles et les tendances passées pour prédire les résultats futurs. Ces modèles sont couramment utilisés dans des domaines tels que la prévision des ventes, la détection de fraudes, la recommandation de produits et le diagnostic médical.
Par exemple, les entreprises de commerce électronique peuvent utiliser des modèles prédictifs pour anticiper les produits que les clients sont susceptibles d’acheter, ce qui peut les aider à personnaliser les recommandations et à améliorer les ventes.
Modèles génératifs : Les modèles génératifs sont des modèles d’IA qui sont capables de générer de nouvelles données qui ressemblent à celles du jeu de données sur lequel ils ont été formés. Ces modèles utilisent des techniques d’apprentissage automatique avancées, telles que les réseaux génératifs antagonistes (GAN), pour créer des données réalistes.
Par exemple, les modèles génératifs peuvent être utilisés pour créer de nouvelles images, de la musique, ou même pour générer du texte de manière cohérente dans un style spécifique.
- LowCode/NoCode : En particulier sur les solutions de Data Visualisation et d’automatisation de workflow de données métiers (RPA). Les solutions de Data Visualisation et d’automatisation de workflows de données métiers par de solutions de LowCode/NoCode offrent des avantages considérables en termes de facilité d’utilisation, de rapidité de développement et d’accessibilité à un large éventail d’utilisateurs, y compris ceux qui ne sont pas des développeurs professionnels (Citizen développeur). Cela permet aux entreprises d’exploiter au mieux leurs données et d’optimiser leurs processus métiers de manière efficace.
Intégrer la data à Impact + : Trajectoire IT4Good
Les données à impacts + représentent l’ensemble des données internes au Si et des données externes permettant de mettre en place des services de mesure, de contrôle et d’aide à la décision sur les impacts environnementaux des usages numérique et/ou physique.
Ces données sont essentielles pour évaluer et comprendre l’impact écologique des activités numériques et physiques d’une entreprise ou d’une organisation. Elles peuvent inclure des informations telles que la consommation d’énergie des infrastructures informatiques, les émissions de gaz à effet de serre générées par les serveurs et les équipements, l’utilisation des ressources naturelles pour la fabrication des dispositifs électroniques, etc.
L’analyse et l’exploitation de ces données à impacts + permettent de mettre en place des stratégies de réduction de l’empreinte environnementale, de concevoir des solutions plus durables, de surveiller les progrès réalisés dans les initiatives de développement durable, et d’aider à la prise de décisions éclairées pour minimiser l’impact négatif sur l’environnement.
Ces données peuvent également être utilisées pour sensibiliser les utilisateurs, les clients et les parties prenantes à l’importance de réduire l’impact environnemental de leurs activités numériques et physiques. En résumé, les données à impacts + jouent un rôle clé dans la transition vers une économie plus respectueuse de l’environnement et dans la gestion responsable des activités technologiques.
- Collecte de données à impacts environnementaux : La collecte de données à impacts environnementaux peut être réalisée à partir de diverses sources, telles que des capteurs environnementaux, des dispositifs de mesure de la consommation énergétique, des bases de données internes de l’organisation, des données provenant de fournisseurs externes, etc. Ces données peuvent être quantitatives (consommation d’énergie, émissions de CO2, quantités de déchets, etc.) ou qualitatives (méthodes de production écologiques, labels de durabilité, etc.).
- Analyse et interprétation des données : Une fois collectées, ces données doivent être analysées pour comprendre l’impact environnemental des activités de l’organisation. Des techniques d’analyse de données, telles que l’apprentissage automatique (machine Learning) et l’analyse statistique, peuvent être utilisées pour identifier les tendances, les gisements d’économies d’énergie, les sources d’émissions, etc.
- Amélioration des performances environnementales : Les données à impacts + permettent aux entreprises et aux organisations de mieux comprendre leur empreinte écologique et d’identifier les domaines dans lesquels des améliorations peuvent être apportées. Cela peut inclure des mesures visant à réduire la consommation d’énergie, à optimiser l’utilisation des ressources naturelles, à adopter des pratiques de production plus durables, etc.
- Évaluation de la durabilité : Les données à impacts environnementaux jouent un rôle crucial dans l’évaluation de la durabilité des activités d’une organisation. Elles aident à déterminer si les pratiques actuelles sont en ligne avec les objectifs de développement durable et à surveiller les progrès réalisés vers des objectifs environnementaux spécifiques.
- Transparence et communication : En mettant en évidence les initiatives durables mises en place et les résultats obtenus, les entreprises peuvent renforcer leur transparence en matière d’impact environnemental. Cela peut également renforcer la confiance des parties prenantes, des clients et du public en général.
- Réglementations et conformité : Dans de nombreux pays, il existe des réglementations environnementales strictes qui obligent les entreprises à surveiller et à rapporter leur impact environnemental. Les données à impacts + sont essentielles pour se conformer à ces réglementations et éviter d’éventuelles sanctions.
- Innovation durable : L’analyse des données à impacts environnementaux peut également inspirer l’innovation dans le développement de nouveaux produits et services. En intégrant la durabilité dans la conception de produits, les entreprises peuvent répondre à la demande croissante des consommateurs pour des solutions respectueuses de l’environnement.